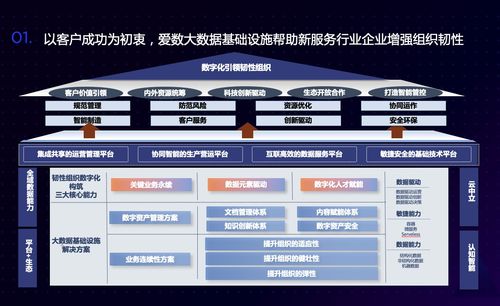
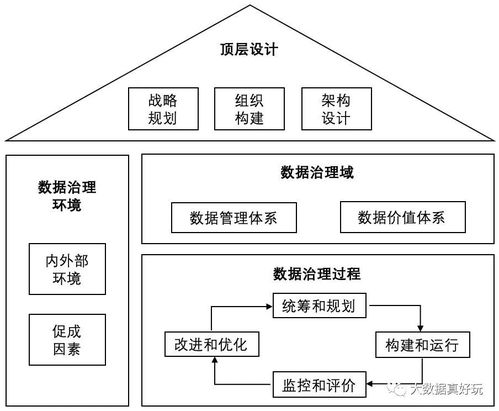
集团多工厂MES架构中数据处理服务的规划方法
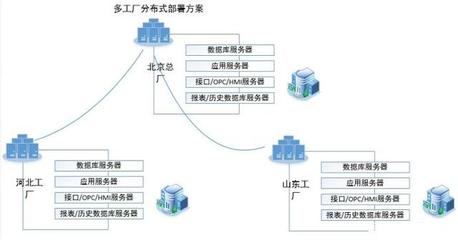
在当今制造业数字化转型的浪潮下,制造执行系统(MES)作为连接企业资源计划(ERP)与生产现场的关键纽带,其数据处理服务的规划尤为关键。尤其对于拥有多个工厂的集团企业,如何设计高效、可扩展且安全的数据处理架构,直接关系到生产运营的效率与决策的精准性。本文将系统性地探讨集团多工厂MES架构中数据处理服务的规划策略,涵盖核心原则、架构设计、关键组件及实施步骤。
一、核心规划原则
- 统一性与标准化:集团层面需制定统一的数据标准和接口规范,确保各工厂数据格式一致,便于跨工厂数据整合与分析。例如,定义统一的生产订单、物料、设备状态数据模型。
- 可扩展性与模块化:架构应支持工厂数量的动态增减,数据处理服务采用模块化设计,如独立的数据采集、存储、计算模块,便于按需扩展。
- 实时性与可靠性:生产数据需实时处理,确保及时反馈生产状态;同时通过冗余设计和故障转移机制保障服务高可用性。
- 安全性与合规性:实施严格的数据访问控制、加密传输及审计日志,满足行业法规(如ISO 27001)和集团内部安全政策。
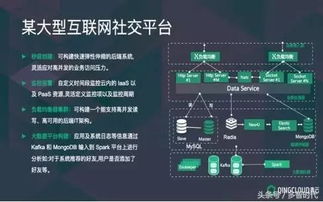
二、数据处理服务架构设计
- 数据采集层:部署轻量级代理或物联网网关于各工厂,负责采集设备数据、生产订单、质量参数等,支持多种协议(如OPC UA、MQTT)。采用边缘计算预处理数据,减少网络负载。
- 数据传输层:通过企业专网或VPN建立安全通道,使用消息队列(如Kafka、RabbitMQ)实现异步数据传输,确保数据有序、可靠地汇集到集团数据中心。
- 数据处理与存储层:在集团层面构建集中式数据湖或数据仓库,利用流处理引擎(如Apache Flink)进行实时数据清洗、转换和聚合;结合批处理(如Spark)处理历史数据。存储方案可选用时序数据库(如InfluxDB)用于实时数据,关系型数据库(如PostgreSQL)存储业务数据。
- 数据服务层:提供RESTful API或GraphQL接口,向各工厂MES应用、集团BI系统及外部系统(如ERP)开放数据服务,支持查询、分析和报表生成。
- 数据治理与监控:建立元数据管理、数据质量监控和生命周期管理机制,通过可视化仪表板实时追踪数据处理性能与异常。
三、关键实施步骤
- 需求分析:评估各工厂的业务流程、数据量和实时性要求,识别共性需求与差异化点。
- 技术选型:根据集团IT基础设施选择合适的技术栈,如云平台(AWS、Azure)或混合部署,优先考虑开源解决方案以降低成本。
- 试点部署:选取一个工厂作为试点,实施数据处理服务,验证架构可行性并收集反馈,迭代优化。
- 全面推广:逐步扩展到其他工厂,确保各节点平滑集成,并提供培训与文档支持。
- 持续优化:定期评估数据处理性能,利用AI/ML技术进行预测性分析,提升数据价值。
四、挑战与应对策略
- 数据孤岛问题:通过标准化接口和中间件打破各工厂数据壁垒,促进数据共享。
- 网络延迟:在边缘节点部署本地缓存和计算能力,降低对中心服务的依赖。
- 运维复杂度:采用容器化(如Docker、Kubernetes)和自动化运维工具,简化部署与管理。
规划集团多工厂MES数据处理服务需以业务为导向,结合技术前沿,构建一个灵活、健壮的数据生态。通过科学的架构设计和分阶段实施,企业不仅能提升生产效率,还能为智能决策奠定坚实基础,驱动制造业的持续创新。
如若转载,请注明出处:http://www.rikmuixpx.com/product/19.html
更新时间:2025-11-29 17:44:12